
 Mint arról már alig egy héttel ezelőtti írásomban beszámoltam, a kubai tudományos közösség egy újabb technológiai mérföldkövet ért el a CecilIA létrehozásával, amely egy fejlett nyelvi modell, és a Havannai Egyetem (UH) Matematika és Számítástechnika Karának Mesterséges Intelligencia (MI) kutatócsoportja munkáját dicséri.
Mint arról már alig egy héttel ezelőtti írásomban beszámoltam, a kubai tudományos közösség egy újabb technológiai mérföldkövet ért el a CecilIA létrehozásával, amely egy fejlett nyelvi modell, és a Havannai Egyetem (UH) Matematika és Számítástechnika Karának Mesterséges Intelligencia (MI) kutatócsoportja munkáját dicséri.
"CecilIA még csak egy kisbaba" - mondja dr. C. Yudivián Almeida Cruz, a Havannai Egyetem Mesterséges Intelligencia Csoportjának igazgatója, a fejlesztőcsapat tagja.
Az igazgatóval Raul Abreu Martin, a Juventud Tecnica c. kubai folyóirat munkatársa beszélgetett.
Miért érdemes kubai szöveggel betanított mesterséges intelligencia alapú nyelvi modellt fejleszteni?
Az hogy kubai szövegből nyelvi modellt hozzunk létre, elengedhetetlen a későbbi generatív mesterséges intelligencia alkalmazások fejlesztéséhez, amelyek megragadják nyelvi sokszínűségünk, kultúránk, hagyományaink és történelmünk árnyalatait.
A nemzeti vagy regionális nyelvi modellek létrehozása és fejlesztése javítja a nemzeti nyelven és annak dialektusaiban végzett feldolgozás minőségét és pontosságát. Az ilyen jellegű modellek hozzájárulnak a nyelvi és kulturális sokszínűség megőrzéséhez is.
Mindezeken túl pedig létezésük lehetővé teszi számunkra a technológiai függőség csökkentését, a nemzeti technológiai innováció elősegítését, valamint a generatív modelleken alapuló vagy azokat használó alkalmazások hozzáférhetőségének és demokratizálásának növelését. Ez lehetővé teszi számunkra, hogy hatékonyabban dolgozzunk az egyes ágazatokra specializálódott hatékonyabb számítástechnikai rendszerek létrehozásán.
 A CecilIA fejlesztőcsapatának tagja Dr. C. Miriam Nicado Garcíával, a Havannai Egyetem rektorával. (Fotó: Az interjúalany jóvoltából.)
A CecilIA fejlesztőcsapatának tagja Dr. C. Miriam Nicado Garcíával, a Havannai Egyetem rektorával. (Fotó: Az interjúalany jóvoltából.)
Hogyan definiálná a CecilIA kubai nyelvi modellt egy nem műszaki beállítottságú személy számára, és melyek a Salmandra 2b architektúra sajátosságai és miért ezt választották a modell alapjának?
A CecilIA durván fogalmazva egy mesterséges intelligencia technikákon és algoritmusokon alapuló rendszerként definiálható, amely megérti és generálja a spanyol nyelvű szövegeket, különös tekintettel a Kubában beszélt spanyol nyelvre.
Ez azt jelenti hogy nemcsak a nyelvet kívánja megragadni, hanem az ország saját kulturális, társadalmi és nyelvi jellemzőit is, például a szólásokat, kifejezéseket és tipikus kulturális utalásokat.
Így segíthet olyan feladatokban, mint a szövegek írása, a kubai közösségi médiában megjelenő érzelmek elemzése, a kubaira jellemző főnevek felismerése vagy a kubai spanyol nyelv variánsaira való érzékeny fordítás.
A közepes vagy kis méretű nyelvi modellnek tekinthető kategóriába tartozik. A nagy nyelvi modellekhez képest ezeknek több korlátjuk van a mély megértés és az összetett gondolkodás tekintetében, és jobban függenek a létrehozáshoz használt adatok minőségétől. Viszont, rövidebb betanítási idővel és alacsonyabb számítási erőforrás - memória továbbá energiafogyasztással rendelkeznek, valamint gyorsabbak és hatékonyabbak bizonyos feladatokhoz.
Az országunk kulturális sajátosságai, technológiai infrastruktúrája és gazdasági képességei miatt a Salamandra 2b volt a legoptimálisabb választás kiindulópontként hogy létrehozzunk egy kubai modellt.
Ezt a döntést a fejlesztőcsapat akadémiai kapcsolatai is ösztönözték.
A Salamandra nyelvi modellcsalád többnyelvű, nyílt forráskódú, és fejlett infrastruktúrán lévő nyílt adatokkal van betanítva.
Különböző verziói léteznek, a paraméterek számától függően. A legkisebb a 2b modell.
Miért fontos a kubai nyelvi modell, CecilIA az ország számára?
A CecilIA, mint a fejlesztés alatt álló modellek családja, egy egyedülálló technológiai eszközt képvisel, amelynek célja a kubai nyelv és kultúra, - beleértve annak nyelvi, társadalmi és történelmi sajátosságait is - mélyreható megértése és tükrözése is egyben.
A nyelvi modellcsalád kifejezés pedig olyan modellek csoportjára utal, amelyek közös mögöttes architektúrával rendelkeznek, de különböző nyelvekre, méretekre vagy célokra taníthatók.
A csoportosítás megkönnyíti a hasonló technikai alapokon nyugvó, de eltérő igényekhez igazított modellek fejlesztését, összehasonlítását és integrációját.
Összegezve a CecilIA még kezdeti szakaszban van, és az alap CecilIA 2b modellen alapul, de a cél az, hogy ezt a családot különböző méretű és specializációjú modellekkel építsük fel. Ezért emlegetjük a CecilIA-t kezdettől fogva nyelvi modellek családjaként.
 CecilIA bemutatójának pillanata. Fotó: (Az interjúalany jóvoltából)
CecilIA bemutatójának pillanata. Fotó: (Az interjúalany jóvoltából)
Ennek a programnak távlati célja hogy hozzájáruljon a technológiai akadályok leküzdéséhez, segítve a mesterséges intelligencia hozzáférhetőbbé és relevánsabbá tételét a kubaiak számára.
Ez különösen értékes a digitális befogadás, a nemzeti technológiai innováció és Kuba sajátos igényeire reagáló alkalmazások fejlesztésének támogatása szempontjából.
Célunk, hogy a CecilIA olyan eszköz legyen amely képessé teszi a kubai kultúrát, nyelvet és egyediséget arra, hogy saját hangot adjanak a digitális átalakulás korában, erősítve hazánk technológiai és kulturális szuverenitását.
Milyen típusú feladatokat nem tud még önállóan elvégezni a CecilIA, és mire lenne szükség ahhoz, hogy képes legyen az utasításokat mint egy társalgási asszisztens?
Az elérhető verzió egy kubai szövegkorpusszal előre betanított alapmodell.
Ez azt jelenti hogy egy általános alapmodell, mely bizonyos szintű konzisztenciával képes kezelni az alapvető természetes nyelvi feladatokat, például a szöveggenerálást, az alapvető nyelvi megértést és a felügyelet nélküli szövegpredikciót.
Azonban finomhangolásra van szükség a pontosságának javítása és az adott alkalmazásokhoz vagy területekhez való alkalmazkodás érdekében.
Ez megtehető úgy, hogy egy adott területre specializálódjon, vagy bizonyos típusú feladatok végrehajtására legyen képes.
Ehhez először egy kifejezetten a CecilIA-ra szabott kubai fókuszú utasításkorpuszt kell létrehozni.
Ha ez megtörtént, a betanítás az alapmodellel történik. Jelenleg azt kell értékelnünk, hogy a CecilIA milyen kulturális és nyelvi sokszínűséget tud tükrözni, mind a jelenlegi verzióban, mind a jövőbeli fejlesztésekben. Ez egy másik kihívás, amellyel közösen kell szembenéznünk, vagyis miként építünk fel egy mércét, amely értékeli a CecilIA kubai identitását...
Ez viszont nem elég, mert a nyelvi modellek önmagukban nem működnek. Azok olyan alkotóelemek, amelyekre olyan rendszerek épülnek, mint például a társalgási asszisztensek. Ez lenne a következő lépés: olyan alkalmazások és számítástechnikai rendszerek létrehozása, amelyek a CecilIA-t építőelemként használják, tekintettel annak jellemzőire.
Miután kifejlesztettük a CecilIA verzióit, közös architektúrájú, rendkívül moduláris és skálázható modelleket kapunk, amelyek hatékonyan és rugalmasan használhatók.
Ez alapul szolgál majd specifikus területekhez, hibrid rendszerek építéséhez és különféle alkalmazások fejlesztéséhez.
Egy olyan eszköznek a fejlesztése mint a ChatGPT, vagy a DeepSeek, nemcsak egy nyelvi modellt igényel hanem számítási rendszer megvalósítását is.
Ennek megtervezése és megvalósítása kivitelezhető ugyan, de jelenleg azonban hiányzik a technológiai infrastruktúra ahhoz, hogy egy mindenkiszámára nyitott, minőségi szolgáltatást nyújtó párbeszédes számítási asszisztenst biztosítsunk.
Hogyan használták a kubai szövegek gyűjtésének és kiválasztásának folyamatát a CelilIA betanításához?
A kubai szövegek korpusza a CecilIA létrehozásának alapja. Ebben az első szakaszban, amelynek célja az alapmodell első verziójának kidolgozása, valamint a létrehozásához szükséges munkafolyamatok megismerése és meghatározása volt.
A korpusz létrehozását a Havannai Egyetem Mesterséges Intelligencia és Adattudományi Csoportján belül végeztük.
Ennek érdekében különböző topológiákból származó adatforrásokat kerestünk, amelyek a kubai kultúra és nyelv különböző aspektusait tükrözhetik.
Fontos volt, hogy a források elérhetőek legyenek a szöveges információk megszerzéséhez. Ettől a ponttól kezdve egy keresési folyamat indult meg, amely magában foglalta az adatbázisok letöltését, weboldalak átkutatását, könyvek, dalok, beszédek és számos más szöveges források keresését.
Az így kapott dokumentumgyűjteménnyel a következő lépés olyan programok fejlesztése volt, amelyek ezeket a szövegeket Markdown-dokumentumokká konvertálják.
Az utolsó lépés pedig a szövegek normalizálása, valamint a formázási problémák és az érvénytelen kódolások észlelése volt. Ezzel egy 2,7 GB méretű szövegből álló első korpuszt kaptunk.
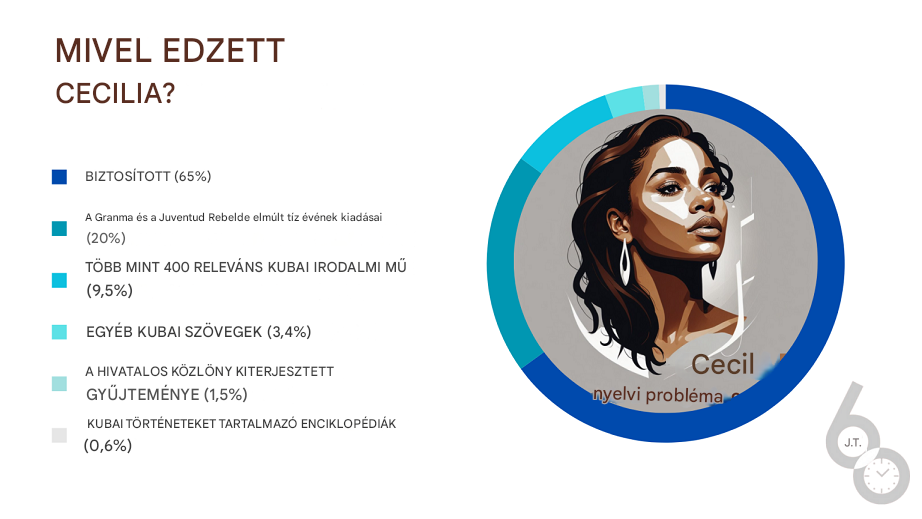 Raul Abrau Martin szemléltető ábrája a nyelvi modell betanításához használt anyagokról.
Raul Abrau Martin szemléltető ábrája a nyelvi modell betanításához használt anyagokról.
A szövegek integrálása az előképzéshez egyszerű, csak szöveges formátumban kell lenniük.
A nehéz dolog mindig a sokszínűségük biztosítása, és jelenleg a köznyelvi szövegkörnyezet ehhez jelentősen alul reprezentált.
Milyen szerepet játszottak az Alicantei Egyetem Nyelvfeldolgozási és Információs Rendszerek Csoportjával (GPLSI), a SYALIA SRL-el és az EPISTEMIAL-al kötött szövetségek?
A GPLSI egy kutatócsoport az Alicentei Egyetemen, amellyel közös programokat irányítottunk és kutatási projekteket fejlesztettünk ki, sőt közösen díjakat is nyertünk a Kubai Tudományos Akadémiától.
Ők azILENA projekt részét képzik, amelynek keretében a Salamandra modellcsaládot is kifejlesztették.
Éppen ezért jelentős ismeretekkel rendelkeznek a nyelvi modellek felépítéséhez szükséges szakértelem területén.
Emellett doktorandusz hallgatóink és professzoraink is részt vesznek ebben a projektben, akik közösen végzik ott kutatásaikat.
"Egy nemrégiben Alicante-ben tett munkalátogatásunk során megvitattunk egy kubai nyelvi modell létrehozásának ötletét.
Az intézmény meglévő nyelvi modellekkel kapcsolatos ismeretei és szakértelme mellett felajánlották számítástechnikai infrastruktúrájukat modelljeink betanításához.
 A CecilIA előképzését Alicente szerverein végeztük, akárcsak a kezdeti értékeléseket. Mindkét folyamatot fiatal kubai kutatók vezették, akik jelenleg a GLPSI-n belül végeznek kutatásokat.
A CecilIA előképzését Alicente szerverein végeztük, akárcsak a kezdeti értékeléseket. Mindkét folyamatot fiatal kubai kutatók vezették, akik jelenleg a GLPSI-n belül végeznek kutatásokat.
A SYALIA SRL, egy kubai mikrovállalkozás és az EPISTEMIAL egy spanyol megfelelője hozzáférést biztosított néhány számítástechnikai erőforráshoz, valamint finanszírozást a Kubán kívül elérhető szolgáltatásokhoz, amelyeket a CecilIA fejlesztésében így fel tudtunk használni.
Hogyan Illeszkedik a CecilIA a spanyol nyelvi modellek nemzetközi környezetébe?
Jelenleg két nagyobb projekt fut a spanyol nyelvterületen. Egyrészt van a Latin - GPT amely egy nagyszerű latin-amerikai nyelvi modell felépítésének útján jár. A definíciója röviden: "egy Latin-Amerikában, Latin-Amerika számára készült nyelvi modell."
A projekt jelentős finanszírozást kapott egy komoly technológiai infrastruktúra kiépítésére.
A modellképzés még nem kezdődött meg, bár a tervek már elkészültek és hamarosan elindul a kezdeményezés.
Raul Abreu Martin interjúját magyar nyelvre fordította, és szerkesztette:
© Juhász Norbert




A bejegyzés trackback címe:
Kommentek:
A hozzászólások a vonatkozó jogszabályok értelmében felhasználói tartalomnak minősülnek, értük a szolgáltatás technikai üzemeltetője semmilyen felelősséget nem vállal, azokat nem ellenőrzi. Kifogás esetén forduljon a blog szerkesztőjéhez. Részletek a Felhasználási feltételekben és az adatvédelmi tájékoztatóban.